Assign modules on offcanvas module position to make them visible in the sidebar.
Categories
Testimonials
- Vous êtes ici :
-
Home

- Technologies
Technologie
Note utilisateur: 0 / 5

- Détails
- Écrit par Alpha Amadou DIALLO
- Affichages : 64033
Note utilisateur: 3 / 5

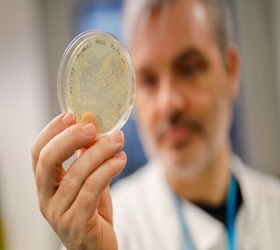
Les scientifiques de Londres sont sur le point de développer un vaccin contre la souche Covid-19 du coronavirus, ont-ils déclaré.
Les essais ont déjà été menés à bien chez la souris et pourraient être prêts pour des essais chez l’homme d’ici juin.
Les expériences sont dirigées à l’Imperial College de Londres par le Dr Robin Shattock, responsable de Mucosal Infection and Immunity.
Ils ont appelé à davantage de financement et déclaré qu’un vaccin pourrait être disponible l’année prochaine.
Le chercheur principal, le Dr Paul McKay, a déclaré au Daily Express: « J’ai des résultats un mois après avoir injecté (les souris) et le vaccin fonctionne vraiment, vraiment bien. »
0 Comments- Détails
- Écrit par Alpha Amadou DIALLO
- Affichages : 51044
Note utilisateur: 3 / 5
Alors que le nombre d’infections à coronavirus dépasse désormais les 120’000 personnes dans le monde, dont plus de 4000 morts, les chercheurs se précipitent pour comprendre pourquoi le virus se propage plus facilement que ses prédécesseurs. Au départ, les autorités annonçaient un facteur de propagation d’environ 3, mais il semblerait que ce chiffre soit plus élevé. Bien qu’il soit encore trop tôt pour statuer sur le taux réel moyen, des chercheurs de l’Université de Washington pensent avoir des éléments de réponse expliquant pourquoi ce nouveau coronavirus est plus contagieux.
Suite à des analyses génétiques et structurelles, les scientifiques ont identifié une caractéristique clé du virus : une protéine de surface qui pourrait expliquer, du moins en partie, pourquoi il infecte si facilement les cellules humaines par rapport à ses prédécesseurs.
« Comprendre la transmission du virus est la clé pour permettre son confinement et sa prévention future », explique David Veesler, virologue structurel à l’Université de Washington à Seattle, qui a publié les résultats de son équipe concernant la protéine virale. L’étude est disponible sur le serveur de préimpression biomédicale bioRxiv.
Actuellement, d’autres groupes de recherche étudient la porte par laquelle le nouveau coronavirus pénètre dans les tissus humains : un récepteur situé sur les membranes cellulaires. Le récepteur cellulaire et la protéine virale offrent tous deux des cibles potentielles pour de futurs traitements, qui pourraient bloquer l’agent pathogène. Mais selon l’état d’avancement actuel des recherches, il est encore trop tôt pour en être certains.
Le nouveau coronavirus, SARS-CoV-2, semble se propager beaucoup plus facilement que celui qui a causé le syndrome respiratoire aigu sévère (SRAS) en 2003, SARS-CoV. En effet, SARS-CoV-2 a infecté plus de dix fois plus de personnes. Cela serait également dû au fait que le nouveau coronavirus se propage alors même que le porteur ne présente pas de symptômes, ce qui n’était pas le cas en 2003.
Site d’activation de la furine : une caractéristique unique à SARS-CoV-2
Pour infecter une cellule, les coronavirus utilisent une protéine « de spike » (ou “de pointe”), qui se lie à la membrane cellulaire par le biais d’un processus activé par des enzymes cellulaires spécifiques. Les analyses génomiques du nouveau coronavirus ont révélé que sa protéine de spike diffère de celles de parents proches, et suggèrent que la protéine possède un site spécifique qui est activé par une enzyme de la cellule hôte, appelée furine.
Il s’agit d’une découverte importante, car la furine se trouve dans de nombreux tissus humains, y compris les poumons, le foie et l’intestin grêle, ce qui signifie que le virus a le potentiel d’attaquer plusieurs organes, explique Li Hua, biologiste des structures à l’Université des sciences et technologies de Huazhong à Wuhan (Chine), où l’épidémie a débuté.
La présente découverte pourrait également expliquer certains des symptômes observés chez les personnes atteintes du COVID-19, tels que l’insuffisance hépatique, explique Li, co-auteure d’une analyse génétique du virus publiée sur le serveur de préimpression ChinaXiv le 23 février. SARS-CoV (2003) et d’autres coronavirus du même genre que le
0 Comments- Détails
- Écrit par Alpha Amadou DIALLO
- Affichages : 38619

Note utilisateur: 3 / 5
Alors que le monde commence à peine à déployer la nouvelle technologie 5G, la Chine a annoncé il y a quelques mois le début de ses recherches sur une technologie 6G. Plusieurs entreprises et institutions de recherche se sont réunies en groupes de travail pour un déploiement planifié dès 2030. Le Japon et les États-Unis ont également fait des déclarations sur des recherches similaires. La 6G, qui pourrait être 8000 fois plus rapide que la 5G, mettrait fin aux smartphones actuels et ouvrirait la voie aux interfaces cerveau-ordinateur ainsi qu’aux bâtiments connectés.
Après avoir démarré des réseaux 5G dans 50 villes fin 2019 et avant la date limite de déploiement initiale, la Chine a officiellement mis l’accent sur l’innovation 6G. Le ministère des Sciences et de la Technologie a dévoilé en novembre 2019 son intention de lancer un effort de recherche coordonné au niveau national, spécifiquement axé sur le développement de la technologie 6G.
Bien que le déploiement de la 5G en soit encore à ses balbutiements et que la plupart des utilisateurs mobiles continuent de fonctionner sur les réseaux 4G, le pays a annoncé jeudi son intention de lancer deux groupes de travail distincts qui se concentreront spécifiquement sur l’avancement de la 6G.
Développement de la 6G : la fin de l’ère des smartphones ?
Un groupe sera composé des ministères concernés, dans le but de promouvoir le développement et la mise en œuvre de la 6G. Tandis que l’autre sera composé de personnes représentant 37 universités, instituts de recherche et entreprises, qui fourniront des conseils et des idées sur les aspects techniques du déploiement de la 6G. Il est également important de noter que, bien que la Chine soit l’un des premiers pays à déployer un système 5G massif, elle a reçu un examen international dans la plupart de ses efforts.
Les chercheurs proposent déjà quelques exemples d’applications révolutionnaires en 6G, y compris des interactions sans fil cerveau-ordinateur, qui introduisent de nouveaux cas d’utilisation qui permettent à la technologie d’être littéralement contrôlée par le cerveau. « Les réseaux sans fil actuels ne peuvent pas vraiment gérer les commandes cérébrales, c’est donc quelque chose de très excitant pour la 6G ».
Ils prévoient également que la 6G inaugurera la « fin de l’ère des smartphones ». Dans les réseaux cellulaires actuels, les appareils communiquent
0 CommentsLire la suite : La future technologie : La 6G pourrait être 8000 fois plus rapide que la 5G.
![]()